|
| Last update: 4 December 2010 |
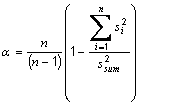
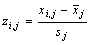
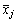 is the mean of the raw data responses in item j and sj is the standard deviation of the raw data responses in item j.
is the mean of the raw data responses in item j and sj is the standard deviation of the raw data responses in item j.
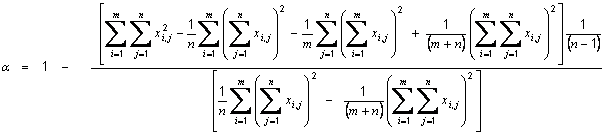
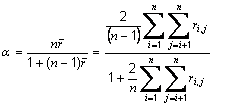
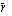 is the average off all Pearson correlation coefficients between items, ri,j is the correlation coefficient between item i and item j and n is the number of items.
is the average off all Pearson correlation coefficients between items, ri,j is the correlation coefficient between item i and item j and n is the number of items.