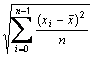
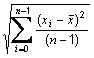
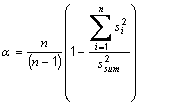
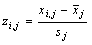
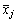 is the mean of the raw data responses in item j and sj is the standard deviation of the raw data responses in item j.
is the mean of the raw data responses in item j and sj is the standard deviation of the raw data responses in item j.
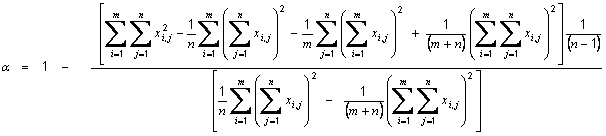

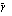 is the average off all Pearson correlation coefficients between items, ri,j is the correlation coefficient between item i and item j and n is the number of items.
is the average off all Pearson correlation coefficients between items, ri,j is the correlation coefficient between item i and item j and n is the number of items.
Set the precision with which floating point numbers are written
public void numberOfDecimalPlaces(int trunc)
Usage: cr.numberOfDecimalPlaces(trunc)
This optional method sets the number of places displayed after the decimal point when floating point numbers are written to an output file. The number of places required is entered via the argument trunc. The default value is 6. The displayed number is the rounded equivalent of the stored number. If the precision of the entered data is greater than the value trunc the output method overides the trunc value and uses the maximum precision of the entered data. See immediately below (numberOfDecimalPlacesAll) for a method that sets the output precision irrespective of the input precision.
public void numberOfDecimalPlacesAll(int trunc)
Usage: cr.numberOfDecimalPlacesAll(trunc)
This optional method sets the number of places displayed after the decimal point when floating point numbers are written to an output file. The number of places required is entered via the argument trunc. The default value is 6. The displayed number is the rounded equivalent of the stored number. The precision set by this method is used in the output irrespective of the precision of the input data. See immediately above (numberOfDecimalPlaces) for a method that sets takes the precision of the entered data into account.
DELETE AN ITEM
public double[][] deleteItem(String itemName)public double[][] deleteItem(int itemIndex)
Usage: newResponseMatrix = cr.deleteItem(itemName)
This method returns a matrix containing the entered data with the item with the name contained in the String itemName deleted. The returned matrix contains any 'no response' replacements in the remaining responses that were made in the original response matrix and will not contain any deletion made to the original data. The format of the returned matrix is responses of each item per column.
Usage: newResponseMatrix = cr.deleteItem(itemIndex)
This method returns a matrix containing the entered data with the item of index itemIndex deleted. The indices run from 1 to n. The returned matrix contains any 'no response' replacements in the remaining responses that were made in the original response matrix and will not contain any deletion made to the original data. The format of the returned matrix is responses of each item per column.
SCATTER PLOTS
Plot of item - item responsespublic void rawItemItemPlot(String itemName1, String itemName2)
public void rawItemItemPlot(int item1Index1, int itemIndex2)
public void standardizedItemItemPlot(String itemName1, String itemName2)
public void standardizedItemItemPlot(int item1Index1, int itemIndex2)
Usage: cr.rawItemItemPlot(itemName1, itemName2)
Calling this method displays, in a new window, a plot of the raw data responses of the item named itemName1 against the raw data responses of the item named itemName2.
Usage: cr.rawItemItemPlot(itemIndex1, itemIndex2)
Calling this method displays, in a new window, a plot of the raw data responses of the item with an index itemIndex1 against the raw data responses of the item with an index itemIndex2. NOTE!! the item indices start at 1 not at 0. See Item Names for methods that return an item index or name.
Usage: cr.standardizedItemItemPlot(itemName1, itemName2)
Calling this method displays, in a new window, a plot of the standardized data responses of the item named itemName1 against the standardized data responses of the item named itemName2.
Usage: cr.standardizedItemItemPlot(itemIndex1, itemIndex2)
Calling this method displays, in a new window, a plot of the standardized data responses of the item with an index itemIndex1 against the standardized data responses of the item with an index itemIndex2. NOTE!! the item indices start at 1 not at 0. See Item Names for methods that return an item index or name.
Plot of item - means of item responses
public void rawItemMeansPlot(String itemName)
public void rawItemMeansPlot(int item1Index)
public void standardizedItemMeansPlot(String itemName)
public void standardizedItemMeansPlot(int item1Index)
Usage: cr.rawItemMeansPlot(itemName)
Calling this method displays, in a new window, a plot of the raw data responses of the item named itemName against the means of the raw data responses of all items.
Usage: cr.rawItemMeansPlot(itemIndex)
Calling this method displays, in a new window, a plot of the raw data responses of the item with an index itemIndex a against the means of the raw data responses of all items. NOTE!! the item indices start at 1 not at 0. See Item Names for methods that return an item index or name.
Usage: cr.standardizedItemMeansPlot(itemName)
Calling this method displays, in a new window, a plot of the standardized data responses of the item named itemName against the means of the standardized data responses of all items.
Usage: cr.standardizedItemMeansPlot(itemIndex)
Calling this method displays, in a new window, a plot of the standardized data responses of the item with an index itemIndex against the means of the standardized data responses of all items. NOTE!! the item indices start at 1 not at 0. See Item Names for methods that return an item index or name.
CORRELATION COEFFICIENTS
BETWEEN ALL ITEMSCorrelation Coefficient Matrix
public double[][] rawCorrelationCoefficients()
public double[][] standardizedCorrelationCoefficients()
Usage: corrCoeff = cr.rawCorrelationCoefficients()
This method returns an (n+1) times (n+1) matrix where n is the number of items. Rows and columns 0 to n-1 contain the correlation coefficients, for the raw data responses, between all pairs of items, e.g. corrCoeff[0][3] contains the correlation coefficient between the first item and the fourth item. Rows and columns n contain the correlation coefficients between the items and the totals of all the items, e.g. corrCoeff[1][n] contains the correlation coefficient, for the raw data responses, between the second item and the totals of all n items.
Usage: corrCoeff = cr.standardizedCorrelationCoefficients()
This method returns an (n+1) times (n+1) matrix where n is the number of items. Rows and columns 0 to n-1 contain the correlation coefficients, for the standardized data responses, between all pairs of items, e.g. corrCoeff[0][3] contains the correlation coefficient between the first item and the fourth item. Rows and columns n contain the correlation coefficients between the items and the totals of all the items, e.g. corrCoeff[1][n] contains the correlation coefficient, for the standardized data responses, between the second item and the totals of all n items.
Average correlation coefficient, excluding totals
public double rawAverageCorrelationCoefficients()
public double standardizedAverageCorrelationCoefficients()
Usage: meanCorrCoeff = cr.rawAverageCorrelationCoefficients()
This method returns, for the raw data responses, the average of all the correlation coefficients between items,
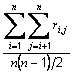
where n is the number of items and ri,j is the correlation coefficient between the ith and jth items. This method does not include, in the average, the correlation coefficients with the totals of all the items (see below).
Usage: meanCorrCoeff = cr.standardizedAverageCorrelationCoefficients()
This method returns, for the standardized data responses, the average of all the correlation coefficients between items,
where n is the number of items and ri,j is the correlation coefficient between the ith and jth items. This method does not include, in the average, the correlation coefficients with the totals of all the items (see below).
Average correlation coefficient, including totals
public double rawStandardDeviationCorrelationCoefficientsWithTotals()
public double standardizedStandardDeviationCorrelationCoefficientsWithTotals()
Usage: meanCorrCoeff = cr.rawStandardDeviationCorrelationCoefficientsWithTotals()
This method returns, for the raw data responses, the average of all the correlation coefficients between items and the totals of all items,
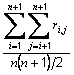
where n is the number of items and ri,j, for i and j less than or equal to n is the correlation coefficient between the ith and jth items and ri,n+1 is the correlation coefficient between the ith item and the totals of all items. See above) for exclusion of totals.
Usage: meanCorrCoeff = cr.standardizedStandardDeviationCorrelationCoefficientsWithTotals()
This method returns, for the standardized data responses, the average of all the correlation coefficients between items and the totals of all items,
where n is the number of items and ri,j, for i and j less than or equal to n is the correlation coefficient between the ith and jth items and ri,n+1 is the correlation coefficient between the ith item and the totals of all items. See above for exclusion of totals.
Standard deviation of the correlation coefficients, excluding totals
public double rawStandardDeviationCorrelationCoefficients()
public double standardizedStandardDeviationCorrelationCoefficients()
Usage: sdCorrCoeff = cr.rawStandardDeviationCorrelationCoefficients()
This method returns, for the raw data responses, the standard deviation of all the correlation coefficients between items. This method does not include, in the average, the correlation coefficients with the totals of all the items (see below).
Usage: sdCorrCoeff = cr.standardizedStandardDeviationCorrelationCoefficients()
This method returns, for the standardized data responses, the standard deviation of all the correlation coefficients between items. This method does not include, in the average, the correlation coefficients with the totals of all the items (see below).
Standard deviation of the correlation coefficients, including totals
public double rawStandardDeviationCorrelationCoefficientsWithTotals()
public double standardizedStandardDeviationCorrelationCoefficientsWithTotals()
Usage: sdCorrCoeff = cr.rawStandardDeviationCorrelationCoefficientsWithTotals()
This method returns, for the raw data responses, the standard deviation of all the correlation coefficients between items and the totals of all items. See above) for exclusion of totals.
Usage: sdCorrCoeff = cr.standardizedStandardDeviationCorrelationCoefficientsWithTotals()
This method returns, for the standardized data responses, the standard deviation of all the correlation coefficients between items and the totals of all items. See above for exclusion of totals.
BETWEEN PAIRS
Item-item pair
public double rawCorrelationCoefficient(String itemName1, String itemName2)
public double rawCorrelationCoefficient(int itemIndex1, int itemIndex2)
public double standardizedCorrelationCoefficient(String itemName1, String itemName2)
public double standardizedCorrelationCoefficient(int itemIndex1, int itemIndex2)
Usage: corrCoeff = cr.rawCorrelationCoefficient(itemName1, itemName2)
This method returns the correlation coefficient, for the raw data responses, between the item with the name contained in the String itemName1 and the item with the name contained in the String itemName2.
Usage: corrCoeff = cr.rawCorrelationCoefficient(itemIndex1, itemIndex2)
This method returns the correlation coefficient, for the raw data responses, between the item of index itemIndex1 and the item of index itemIndex2. The indices run from 1 to n.
Usage: corrCoeff = cr.standardizedCorrelationCoefficient(itemName1, itemName2)
This method returns the correlation coefficient, for the standardized data responses, between the item with the name contained in the String itemName1 and the item with the name contained in the String itemName2.
Usage: corrCoeff = cr.standardizedCorrelationCoefficient(itemIndex1, itemIndex2)
This method returns the correlation coefficient, for the standardized data responses, between the item of index itemIndex1 and the item of index itemIndex2. The indices run from 1 to n.
Item-(totals of all items) pair
public double rawCorrelationCoefficient(String itemName)
public double rawCorrelationCoefficient(int itemIndex)
public double standardizedCorrelationCoefficient(String itemName)
public double standardizedCorrelationCoefficient(int itemIndex)
Usage: corrCoeff = cr.rawCorrelationCoefficient(itemName)
This method returns the correlation coefficient, for the raw data responses, between the item with the name contained in the String itemName and the totals of all items.
Usage: corrCoeff = cr.rawCorrelationCoefficient(itemIndex)
This method returns the correlation coefficient, for the raw data responses, between the item of index itemIndex and the totals of all items. The indices run from 1 to n.
Usage: corrCoeff = cr.standardizedCorrelationCoefficient(itemName1)
This method returns the correlation coefficient, for the standardized data responses, between the item with the name contained in the String itemName1 and the totals of all items.
Usage: corrCoeff = cr.standardizedCorrelationCoefficient(itemIndex)
This method returns the correlation coefficient, for the standardized data responses, between the item of index itemIndex aand the totals of all items. The indices run from 1 to n.
COVARIANCES
BETWEEN ALL ITEMSCovariance Matrix
public double[][] rawCovariances()
public double[][] standardizedCovariances()
Usage: covar = cr.rawCovariances()
This method returns an (n+1) times (n+1) matrix where n is the number of items. Rows and columns 0 to n-1 contain the covariances, for the raw data responses, between all pairs of items, e.g. corrCoeff[0][3] contains the covariance between the first item and the fourth item. Rows and columns n contain the covariances between the items and the totals of all the items, e.g. corrCoeff[1][n] contains the covariance, for the raw data responses, between the second item and the totals of all n items. The diagonal elements contain the variances, e.g. covar[2][2] contins the variance of the third item.
See Setting the denominator for covariance formulae options.
Usage: covar = cr.standardizedCovariances()
This method returns an (n+1) times (n+1) matrix where n is the number of items. Rows and columns 0 to n-1 contain the covariances, for the standardized data responses, between all pairs of items, e.g. corrCoeff[0][3] contains the covariance between the first item and the fourth item. Rows and columns n contain the covariances between the items and the totals of all the items, e.g. corrCoeff[1][n] contains the covariance, for the standardized data responses, between the second item and the totals of all n items. The diagonal elements contain the variances, e.g. covar[2][2] contins the variance of the third item.
See Setting the denominator for covariance formulae options.
BETWEEN PAIRS
Item-item pair
public double rawCovariance(String itemName1, String itemName2)
public double rawCovariance(int itemIndex1, int itemIndex2)
public double standardizedCovariance(String itemName1, String itemName2)
public double standardizedCovariance(int itemIndex1, int itemIndex2)
Usage: covar = cr.rawCovariance(itemName1, itemName2)
This method returns the covariance, for the raw data responses, between the item with the name contained in the String itemName1 and the item with the name contained in the String itemName2.
Usage: covar = cr.rawCovariance(itemIndex1, itemIndex2)
This method returns the covariance, for the raw data responses, between the item of index itemIndex1 and the item of index itemIndex2. The indices run from 1 to n.
Usage: covar = cr.standardizedCovariance(itemName1, itemName2)
This method returns the covariance, for the standardized data responses, between the item with the name contained in the String itemName1 and the item with the name contained in the String itemName2.
Usage: covar = cr.standardizedCovariance(itemIndex1, itemIndex2)
This method returns the covariance, for the standardized data responses, between the item of index itemIndex1 and the item of index itemIndex2. The indices run from 1 to n.
See Setting the denominator for covariance formulae options.
Item-(totals of all items) pair
public double rawCovariance(String itemName)
public double rawCovariance(int itemIndex)
public double standardizedCovariance(String itemName)
public double standardizedCovariance(int itemIndex)
Usage: covar = cr.rawCovariance(itemName)
This method returns the covariance, for the raw data responses, between the item with the name contained in the String itemName and the totals of all items.
Usage: covar = cr.rawCovariance(itemIndex)
This method returns the covariance, for the raw data responses, between the item of index itemIndex and the totals of all items. The indices run from 1 to n.
Usage: covar = cr.standardizedCovariance(itemName1)
This method returns the covariance, for the standardized data responses, between the item with the name contained in the String itemName1 and the totals of all items.
Usage: covar = cr.standardizedCovariance(itemIndex)
This method returns the covariance, for the standardized data responses, between the item of index itemIndex aand the totals of all items. The indices run from 1 to n.
See Setting the denominator for covariance formulae options.
ITEM MEANS
MEAN VALUES OF ALL ITEMSRaw data
public double[] rawItemMeans()
Usage: itemMeans = cr.rawItemMeans()
This method returns the means, calculated using the raw data, of all the items. The order of items is as entered minus any deleted due to missing responses.
Standardized data
public double[] standardizedItemMeans()
Usage: itemMeans = cr.standardizedItemMeans()
This method returns the means, calculated using standardized data, of all the items. The order of items is as entered minus any deleted due to missing responses.
MEAN VALUE OF AN INDIVIDUAL ITEM
Raw data
public double rawItemMean(int index)
public double rawItemMean(String name)
Usage: itemMean = cr.rawItemMean(item)
This method returns the mean, calculated using the raw data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
Standardized data
public double standardizedItemMean(int index)
public double standardizedItemMean(String name)
Usage: itemMean = cr.standardizedItemMean(item)
This method returns the mean, calculated using standardized data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
MEAN VALUE OF ALL ITEM MEANS
Raw data
public double rawMeanOfItemMeans()
Usage: itemMeanOfMeans = cr.rawMeanOfItemMeans()
This method returns the mean, calculated using the raw data, of the means of all items.
Standardized data
public double standardizedMeanOfItemMeans()
Usage: itemMeanOfMeans = cr.standardizedMeanOfItemMeans()
This method returns the mean, calculated using standardized data, of the means of all items.
STANDARD DEVIATION OF ALL ITEM MEANS
Raw data
public double rawStandardDeviationOfItemMeans()
Usage: itemSdOfMeans = cr.rawStandardDeviationOfItemMeans()
This method returns the standard deviation, calculated using the raw data, of the means of all items.
Standardized data
public double[] standardizedStandardDeviationOfItemMeans()
Usage: itemSdOfMeans = cr.standardizedStandardDeviationOfItemMeans()
This method returns the standard deviation, calculated using standardized data, of the means of all items.
See Setting the denominator for standard deviation formulae options.
VARIANCE OF ALL ITEM MEANS
Raw data
public double rawVarianceOfItemMeans()
Usage: itemVarOfMeans = cr.rawVarianceOfItemMeans()
This method returns the variance, calculated using the raw data, of the means of all items.
Standardized data
public double[] standardizedVarianceOfItemMeans()
Usage: itemVarOfMeans = cr.standardizedVarianceOfItemMeans()
This method returns the variance, calculated using standardized data, of the means of all items.
See Setting the denominator for variance formulae options.
MAXIMUM OF ALL ITEM MEANS
Raw data
public double rawMaximumOfItemMeans()
Usage: itemMaxOfMeans = cr.rawMaximumOfItemMeans()
This method returns the maximum, calculated using the raw data, of the means of all items.
Standardized data
public double[] standardizedMaximumOfItemMeans()
Usage: itemMaxOfMeans = cr.standardizedMaximumOfItemMeans()
This method returns the maximum, calculated using standardized data, of the means of all items.
MINIMUM OF ALL ITEM MEANS
Raw data
public double rawMinimumOfItemMeans()
Usage: itemMinOfMeans = cr.rawMinimumOfItemMeans()
This method returns the minimum, calculated using the raw data, of the means of all items.
Standardized data
public double[] standardizedMinimumOfItemMeans()
Usage: itemMinOfMeans = cr.standardizedMinimumOfItemMeans()
This method returns the minimum, calculated using standardized data, of the means of all items.
RANGE OF ALL ITEM MEANS
Raw data
public double rawRangeOfItemMeans()
Usage: itemRangeOfMeans = cr.rawRangeOfItemMeans()
This method returns the range, calculated using the raw data, of the means of all items.
Standardized data
public double[] standardizedRangeOfItemMeans()
Usage: itemRangeOfMeans = cr.standardizedRangeOfItemMeans()
This method returns the range, calculated using standardized data, of the means of all items.
ITEM MOMENT SKEWNESS
The moment skewness of an item is defined as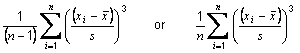
where xi are the responses to the item in question,
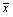 is the sample mean of the item and s is the sample standard deviation of the item.
is the sample mean of the item and s is the sample standard deviation of the item.The default denominator is (n−1). See Setting the denominator for methods resetting the denominator.
MOMENT SKEWNESS OF ALL ITEMS
Raw data
public double[] rawItemMomentSkewnessess()
Usage: skewness = cr.rawItemMomentSkewnessess()
This method returns the moment skewnesses, calculated using the raw data, of all the items. The order of items is as entered minus any deleted due to missing responses.
Standardized data
public double[] standardizedItemMomentSkewnessess() Usage: skewness = cr.standardizedItemMomentSkewnessess()
This method returns the moment skewnesses, calculated using standardized data, of all the items. The order of items is as entered minus any deleted due to missing responses.
MOMENT SKEWNESS OF AN INDIVIDUAL ITEM
Raw data
public double rawItemMomentSkewness(int index)
public double rawItemMomentSkewness(String name)
Usage: skewness = cr.rawItemMomentSkewness(item)
This method returns the moment skewness, calculated using the raw data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
Standardized data
public double standardizedItemMomentSkewness(int index)
public double standardizedItemMomentSkewness(String name)
Usage: skewness = cr.standardizedItemMomentSkewness(item)
This method returns the moment skewness, calculated using standardized data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
ITEM MEDIAN SKEWNESS (Pearson's median skewness coefficient)
The median skewness of an item is defined as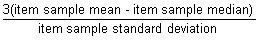
See Setting the denominator for standard deviation formulae options.
MEDIAN SKEWNESS OF ALL ITEMS
Raw data
public double[] rawItemMedianSkewnessess()
Usage: skewness = cr.rawItemMedianSkewnessess()
This method returns the median skewnesses, calculated using the raw data, of all the items. The order of items is as entered minus any deleted due to missing responses.
Standardized data
public double[] standardizedItemMedianSkewnessess()
Usage: skewness = cr.standardizedItemMedianSkewnessess()
This method returns the median skewnesses, calculated using standardized data, of all the items. The order of items is as entered minus any deleted due to missing responses.
MEDIAN SKEWNESS OF AN INDIVIDUAL ITEM
Raw data
public double rawItemMedianSkewness(int index)
public double rawItemMedianSkewness(String name)
Usage: skewness = cr.rawItemMedianSkewness(item)
This method returns the median skewness, calculated using the raw data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
Standardized data
public double standardizedItemMedianSkewness(int index)
public double standardizedItemMedianSkewness(String name)
Usage: skewness = cr.standardizedItemMedianSkewness(item)
This method returns the median skewness, calculated using standardized data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
ITEM QUARTILE SKEWNESS (Bowley skewness coefficient)
The quartile skewness of an item is defined as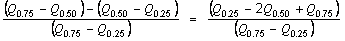
where the Qs denote the interquartile ranges of the item.
QUARTILE SKEWNESS OF ALL ITEMS
Raw data
public double[] rawItemMedianSkewnessess()
Usage: skewness = cr.rawItemQuartileSkewnessess()
This method returns the quartile skewnesses, calculated using the raw data, of all the items. The order of items is as entered minus any deleted due to missing responses.
Standardized data
public double[] rawItemQuartileSkewnessess()
Usage: skewness = cr.standardizedItemQuartileSkewnessess()
This method returns the quartile skewnesses, calculated using standardized data, of all the items. The order of items is as entered minus any deleted due to missing responses.
QUARTILE SKEWNESS OF AN INDIVIDUAL ITEM
Raw data
public double rawItemQuartileSkewness(int index)
public double rawItemQuartileSkewness(String name)
Usage: skewness = cr.rawItemMedianSkewness(item)
This method returns the quartile skewness, calculated using the raw data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
Standardized data
public double standardizedItemQuartileSkewness(int index)
public double standardizedItemQuartileSkewness(String name)
Usage: skewness = cr.standardizedItemMedianSkewness(item)
This method returns the quartile skewness, calculated using standardized data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
ITEM EXCESS KURTOSIS
The excess kurtosis of an item is defined as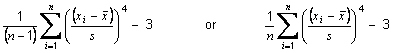
where xi are the responses to the item in question,
is the sample mean of the item and s is the sample standard deviation opf the item, i.e. returns the kurtosis of the item minus the kurtosis of a Gaussian distribution (3.0).The default denominator is (n−1). See Setting the denominator for methods resetting the denominator.
EXCESS KURTOSES OF ALL ITEMS
Raw data
public double[] rawItemExcessKurtoses()
Usage: kurtoses = cr.rawItemExcessKurtoses()
This method returns the excess kurtoses, calculated using the raw data, of all the items. The order of items is as entered minus any deleted due to missing responses.
Standardized data
public double[] standardizedItemExcesskurtoses()
Usage: kurtoses = cr.standardizedItemExcesskurtoses()
This method returns the excess kurtoses, calculated using standardized data, of all the items. The order of items is as entered minus any deleted due to missing responses.
EXCESS KURTOSIS OF AN INDIVIDUAL ITEM
Raw data
public double rawItemExcessKurtosis(int index)
public double rawItemExcessKurtosis(String name)
Usage: kurtosis = cr.rawItemExcessKurtosis(item)
This method returns the excess kurtosis, calculated using the raw data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
Standardized data
public double standardizedItemExcessKurtosis(int index)
public double standardizedItemExcessKurtosis(String name)
Usage: kurtosis = cr.standardizedItemExcessKurtosis(item)
This method returns the excess kurtosis, calculated using standardized data, of an individual item. The item may be identified (argument item) by its index or its name. Note that the order of items starts at 1 and NOT 0. The order is as entered minus any deleted due to missing responses.
ITEM NAMES AND INDICES
NAMES OF THE USED ITEMSpublic String[] itemNames()
Usage: names = cr.itemNames()
This method returns the names of the items used, i.e. after any deletions due to 'missing responses'.
NAMES OF THE ENTERED ITEMS
public String[] originalItemNames()
Usage: names = cr.originalItemNames()
This method returns the names of the items originally entered, i.e. before any deletions due to 'missing responses'.
NAMES OF ANY DELETED ITEMS
public String[] deletedItemsNames()
Usage: names = cr.deletedItemsNames()
This method returns the names of items originally entered but then deleted as part of the 'missing responses' handling. If no items have been deleted null is returned.
INDEX OF AN ITEM
public int itemIndex(String name)
Usage: index = cr.itemIndex(name)
This method returns the index of the item whose name is passed to the method as the argument name. NOTE the indices of names start at 1 and NOT at zero.
NAME OF AN ITEM
public String itemName(int index)
Usage: name = cr.itemName(index)
This method returns the name of the item whose index is passed to the method as the argument index. NOTE the indices of names start at 1 and NOT at zero.
NUMBER OF ITEMS
Number of items usedpublic int usedNumberOfItems()
Usage: num = cr.usedNumberOfItems()
This method returns the number of items used, i.e. after any deletions due to the 'missing response' handling.
Number of items entered
public int originalNumberOfItems()
Usage: num = cr.originalNumberOfItems()
This method returns the number of items entered, i.e. before any deletions due to the 'missing response' handling.
Number of items deleted
public int numberOfDeletedItems()
Usage: num = cr.numberOfDeletedItems()
This method returns the number of items deleted due to the 'missing response' handling.
PERSON INDICES
INDICES OF THE USED PERSONSpublic String[] personIndices()
Usage: names = cr.personIndices()
This method returns the indices of the persons used, i.e. after any deletions due to 'missing responses'. NOTE the indices of the persons start at 1 and NOT at zero.
INDICES OF ANY DELETED PERSONSS
public String[] deletedPersonsIndices()
Usage: names = cr.deletedPersonsIndices()
This method returns the indices of items originally entered but then deleted as part of the 'missing responses' handling. NOTE the indices of the persons start at 1 and NOT at zero.
NUMBER OF PERSONS
Number of persons usedpublic int usedNumberOfPersons()
Usage: num = cr.usedNumberOfPersons()
This method returns the number of persons used, i.e. after any deletions due to the 'missing response' handling.
Number of persons entered
public int originalNumberOfPersons()
Usage: num = cr.originalNumberOfPersons()
This method returns the number of persons entered, i.e. before any deletions due to the 'missing response' handling.
Number of persons deleted
public int numberOfDeletedPersons()
Usage: num = cr.numberOfDeletedPersons()
This method returns the number of persons deleted due to the 'missing response' handling.
RESPONSES
ORIGINAL RESONSESResponses as originally entered
public Object originalScores()
Usage: originalData = cr.originalScores()
This method returns the responses as originally entered, i.e. before any deletions. They are returned as a Java Object as they may have been entered as String[][], double[][], float[][], int[][], char[][], boolean[][] or Matrix. If they were originally read in from a text file the returned Object is of type String[][].
Original responses as row per item
public double[][] originalScoresAsRowPerItem()
Usage: originalData = cr.originalScoresAsRowPerItem()
This method returns the original responses entered rearranged as a two dimensional array of doubles orgainized as a row of responses for each item. Missing responses are returned as Double.NaN.
Original responses as row per person
public double[][] originalScoresAsRowPerPerson()
Usage: originalData = cr.originalScoresAsRowPerPerson()
This method returns the original responses entered rearranged as a two dimensional array of doubles orgainized as a row of responses for each person. Missing responses are returned as Double.NaN.
RESPONSES AS USED (RAW DATA)
Responses as used as row per item
public double[][] usedScoresAsRowPerItem()
Usage: data = cr.usedScoresAsRowPerItem()
This method returns the raw data responses as used, i.e. minus any deleted items or persons, arranged as a two dimensional array of doubles orgainized as a row of responses for each item. Retained missing responses are returned with the chosen substituted values.
Responses as used as row per person
public double[][] usedScoresAsRowPerItem()
Usage: data = cr.usedScoresAsRowPerPerson()
This method returns the raw data responses as used, i.e. minus any deleted items or persons, arranged as a two dimensional array of doubles orgainized as a row of responses for each person. Retained missing responses are returned with the chosen substituted values.
RESPONSES AS USED (STANDARDIZED DATA)
Standardized responses as used as row per item
public double[][] standardizedScoresAsRowPerItem()
Usage: data = cr.standardizedScoresAsRowPerItem()
This method returns the standardized data responses as used, i.e. minus any deleted items or persons, arranged as a two dimensional array of doubles orgainized as a row of responses for each item. Retained missing responses are returned with the chosen standardized substituted values.
Standardized responses as used as row per person
public double[][] standardizedScoresAsRowPerItem()
Usage: data = cr.standardizedScoresAsRowPerPerson()
This method returns the standardized data responses as used, i.e. minus any deleted items or persons, arranged as a two dimensional array of doubles orgainized as a row of responses for each person. Retained missing responses are returned with the chosen standardized substituted values.
ITEM NAME AND PERSON INDEX OF THE REPLACED RESPONSES
Standardized responses as used as row per item
public String[] indicesOfReplacedScores()
Usage: repl = cr.ndicesOfReplacedScores()
This method returns the item name and person index for all 'missing responses' that have been replaced rather than deleted. NOTE that the indices of the persons starts at 1 NOT at 0.
NUMBER OF RESPONSES
Original number of scores
public int originalTotalNumberOfScores()
Usage: nScores = cr.originalTotalNumberOfScores()
This method returns the original number of responses entered, i.e. before any deletions.
Number of scores used
public int usedTotalNumberOfScores()
Usage: nScores = cr.usedTotalNumberOfScores()
This method returns the number of responses used, i.e. after any deletions.
Number of deleted scores
public int numberOfDeletedScores()
Usage: nDeletes = cr.numberOfDeletedScores()
This method returns the number of responses that have been deleted in the handling of any 'missing responses'.
Number of replacement scores
public int numberOfReplacedScores()
Usage: nDeletes = cr.numberOfReplacedScores()
This method returns the number of responses that have been replaced in the handling of any 'missing responses'.
SOME OF THE DOCUMENTATION IS STILL UNDER CONSTRUCTION
Some of the item statistic methods, e.g. rawItemStandardDeviation(), person statistic methods, e.g. standardizedPersonVariances(), and allResponses statistic methods, e.g. rawAllResponsesMaximum(), have still to be fully documented. All of these follow the same format as that of the corresponding methods in the Item Means methods documented above. Their full individual documentation will be added later.
EXAMPLE PROGRAM
An example program, CronbachAnalysis, and the associated documentation may be found on Cronbach Analysis.OTHER CLASSES USED BY THIS CLASS
This class uses the following classes in this library:This page was prepared by Dr Michael Thomas Flanagan