|
| Constructor | public Scores() | ||
| Enter the data | Read title, item names and responses from text file |
Enter responses as rows per person |
public void readScoresAsRowPerPersonA() |
| public void readScoresAsRowPerPersonA(String filename) | |||
| public void readScoresAsRowPerPersonB() | |||
| public void readScoresAsRowPerPersonB(String filename) | |||
| public void readScoresAsRowPerPersonC() | |||
| public void readScoresAsRowPerPersonC(String filename) | |||
| public void readScoresAsRowPerPersonD() | |||
| public void readScoresAsRowPerPersonD(String filename) | |||
| Enter responses as rows per item |
public void readScoresAsRowPerItemA() | ||
| public void readScoresAsRowPerItemA(Stringfilename) | |||
| public void readScoresAsRowPerItemB() | |||
| public void readScoresAsRowPerItemB(Stringfilename) | |||
| public void readScoresAsRowPerItemC() | |||
| public void readScoresAsRowPerItemC(Stringfilename) | |||
| public void readScoresAsRowPerItemD() | |||
| public void readScoresAsRowPerItemD(Stringfilename) | |||
| Enter data via program arrays and Strings |
Enter responses as rows per person |
public void enterScoresAsRowPerPerson(String[][] responses) | |
| public void enterScoresAsRowPerPerson(double[][] responses) | |||
| public void enterScoresAsRowPerPerson(float[][] responses) | |||
| public void enterScoresAsRowPerPerson(int[][] responses) | |||
| public void enterScoresAsRowPerPerson(char[][] responses) | |||
| public void enterScoresAsRowPerPerson(boolean[][] responses) | |||
| public void enterScoresAsRowPerPerson(Matrix responses) | |||
| Enter responses as rows per item |
public void enterScoresAsRowPerItem(String[][] responses) | ||
| public void enterScoresAsRowPerItem(double[][] responses) | |||
| public void enterScoresAsRowPerItem(float[][] responses) | |||
| public void enterScoresAsRowPerItem(int[][] responses) | |||
| public void enterScoresAsRowPerItem(char[][] responses) | |||
| public void enterScoresAsRowPerItem(boolean[][] responses) | |||
| public void enterScoresAsRowPerItem(Matrix responses) | |||
| Enter title | public void enterTitle(String title) | ||
| Enter item names | public void enterItemNames(String[] itemNames) | ||
| Preprocess the entered data | public void preprocessData() | ||
| Additional data entry options | Suspend reading letters as numerals | public void suspendLetterToNumeral() | public void letterToNumeral() |
| Dichotomous data pairs | Declare data as dichotomous | public void declareDataDichotomous() | |
| Reset numerical representation | public void resetDichotomousYesTrue(double newYesTrue) | ||
| public void resetDichotomousNoFalse(double newNoFalse) | |||
| Get numerical representation | public double getDichotomousYesTrue() | ||
| public double getDichotomousNoFalse() | |||
| Additional dichotomous data pairs | public void additionalDichotomousPairs(String falseSign, String trueSign) | ||
| Missing response handling |
Deletions | Persons | public void setPersonDeletionPercentage(double percentage) |
| Items | public void setItemDeletionPercentage(double percentage) | ||
| Replacements | public void setMissingDataOption(int option) | ||
|
Set the denominator (variance, standard deviation etc.) | Set to n | public void setDenominatortoN() | |
| Set to n-1 | public void setDenominatortoNminusOne() | ||
| Output processed data and output file options |
Output processed data | public void outputProcessedData(String filename) | |
| public void outputProcessedData() | |||
| public void outputProcessedDataAlternate(String filename) | |||
| public void outputProcessedDataAlternate() | |||
| Set output file type | public void setOutputFileType(int option) | ||
| Set incremented numbering of the output file | public void setFileNumbering() | ||
| Remove incremented numbering of the output file | public void removeFileNumbering() | ||
| Set output precision | public void numberOfDecimalPlaces(int trunc) | ||
| public void numberOfDecimalPlacesAll(int trunc) | |||
| Scatter plots | Plot of item - item responses | raw data | public void rawItemItemPlot(String itemName1, String itemName2) |
| public void rawItemItemPlot(int itemIndex1, int itemIndex2) | |||
| standardized data | public void standardizedItemItemPlot(String itemName1, String itemName2) | ||
| public void standardizedItemItemPlot(int itemIndex1, int itemIndex2) | |||
| Plot of item - mean of items responses | raw data | public void rawItemMeansPlot(String itemName) | |
| public void rawItemMeansPlot(int itemIndex) | standardized data | public void standardizedItemMeansPlot(String itemName) | |
| public void standardizedItemMeansPlot(int itemIndex) | |||
| Delete an item | delete by name | public double[][] deleteItem(String itemName) | |
| delete by index | public double[][] deleteItem(int itemIndex) | ||
| Correlation coefficients | Between all items | Correlation coefficient matrix | public double[][] rawCorrelationCoefficients() |
| public double[][] standardizedCorrelationCoefficients() | |||
| Average correlation coefficient | public double rawAverageCorrelationCoefficients() | ||
| public double standardizedAverageCorrelationCoefficients() | |||
| Average correlation coefficient including item totals |
public double rawAverageCorrelationCoefficientsWithTotals() | ||
| public double standardizedAverageCorrelationCoefficientsWithTotals() | |||
| Standard deviation of the correlation coefficients | public double rawStandardDeviationCorrelationCoefficients() | ||
| public double standardizedStandardDeviationCorrelationCoefficients() | |||
| Standard deviation of the correlation coefficient including item totals |
public double rawStandardDeviationCorrelationCoefficientsWithTotals() | ||
| public double standardizedStandardDeviationCorrelationCoefficientsWithTotals() | Between pairs | Item-item pair | public double rawCorrelationCoefficient(String itemName1, String itemName2) |
| public double rawCorrelationCoefficient(int itemIndex1, int itemIndex2) | public double standardizedCorrelationCoefficient(String itemName1, String itemName2) | ||
| public double standardizedCorrelationCoefficient(int itemIndex1, int itemIndex2) | Item-(totals of the items) pair | public double rawCorrelationCoefficient(String itemName) | |
| public double rawCorrelationCoefficient(int itemIndex) | public double standardizedCorrelationCoefficient(String itemName) | ||
| public double standardizedCorrelationCoefficient(int itemIndex) | |||
| Covariances | Between all items | Covariance matrix | public double[][] rawCovariances() |
| public double[][] standardizedCovariances() | Between pairs | Item-item pair | public double rawCovariance(String itemName1, String itemName2) |
| public double rawCovariance(int itemIndex1, int itemIndex2) | public double standardizedCovariance(String itemName1, String itemName2) | ||
| public double standardizedCovariance(int itemIndex1, int itemIndex2) | Item-(totals of the items) pair | public double rawCovariance(String itemName) | |
| public double rawCovariance(int itemIndex) | public double standardizedCovariance(String itemName) | ||
| public double standardizedCovariance(int itemIndex) | |||
| Item means | Mean values of all items | Raw data | public double[] rawItemMeans() |
| Standardized data | public double[] standardizedItemMeans() | ||
| Mean value of an individual item | Raw data | public double rawItemMean(int index) | |
| public double rawItemMean(String name) | |||
| Standardized data | public double standardizedItemMean(int index) | ||
| public double standardizedItemMean(String name) | |||
| Mean value of all item means | Raw data | public double rawMeanOfItemMeans() | |
| Standardized data | public double standardizedMeanOfItemMeans() | ||
| Standard deviation of all item means | Raw data | public double rawStandardDeviationOfItemMeans() | |
| Standardized data | public double standardizedStandardDeviationOfItemMeans() | ||
| Variance of all item means | Raw data | public double rawVarianceOfItemMeans() | |
| Standardized data | public double standardizedVarianceOfItemMeans() | ||
| Maximum of all item means | Raw data | public double rawMaximumOfItemMeans() | |
| Standardized data | public double standardizedMaximumOfItemMeans() | ||
| Minimum of all item means | Raw data | public double rawMinimumOfItemMeans() | |
| Standardized data | public double standardizedMinimumOfItemMeans() | ||
| Range of all item means | Raw data | public double rawRangeOfItemMeans() | |
| Standardized data | public double standardizedRangeOfItemMeans() | ||
| Item standard deviations | Standard deviations of all items | Raw data | public double[] rawItemStandardDeviations() |
| Standardized data | public double[] standardizedItemStandardDeviations() | ||
| Standard deviation value of an individual item | Raw data | public double rawItemStandardDeviation(int index) | |
| public double rawItemStandardDeviation(String name) | |||
| Standardized data | public double standardizedItemStandardDeviation(int index) | ||
| public double standardizedItemStandardDeviation(String name) | |||
| Mean value of all item standard deviations | Raw data | public double rawMeanOfItemStandardDeviations() | |
| Standardized data | public double standardizedMeanOfItemStandardDeviations() | ||
| Standard deviation of all item standard deviations | Raw data | public double rawStandardDeviationOfItemStandardDeviations() | |
| Standardized data | public double standardizedStandardDeviationOfItemStandardDeviations() | ||
| Variance of all item standard deviations | Raw data | public double rawVarianceOfItemStandardDeviations() | |
| Standardized data | public double standardizedVarianceOfItemStandardDeviations() | ||
| Maximum of all item standard deviations | Raw data | public double rawMaximumOfItemStandardDeviations() | |
| Standardized data | public double standardizedMaximumOfItemStandardDeviations() | ||
| Minimum of all item standard deviations | Raw data | public double rawMinimumOfItemStandardDeviations() | |
| Standardized data | public double standardizedMinimumOfItemStandardDeviations() | ||
| Range of all item standard deviations | Raw data | public double rawRangeOfItemStandardDeviations() | |
| Standardized data | public double standardizedRangeOfItemStandardDeviations() | ||
| Item variances | Variances of all items | Raw data | public double[] rawItemVariances() |
| Standardized data | public double[] standardizedItemVariances() | ||
| Variance of an individual item | Raw data | public double rawItemVariance(int index) | |
| public double rawItemVariance(String name) | |||
| Standardized data | public double standardizedItemVariance(int index) | ||
| public double standardizedItemVariance(String name) | |||
| Mean value of all item variances | Raw data | public double rawMeanOfItemVariances() | |
| Standardized data | public double standardizedMeanOfItemVariances() | ||
| Standard deviation of all item variances | Raw data | public double rawVarianceOfItemVariances() | |
| Standardized data | public double standardizedVarianceOfItemVariances() | ||
| Variance of all item variances | Raw data | public double rawVarianceOfItemVariances() | |
| Standardized data | public double standardizedVarianceOfItemVariances() | ||
| Maximum of all item variances | Raw data | public double rawMaximumOfItemVariances() | |
| Standardized data | public double standardizedMaximumOfItemVariances() | ||
| Minimum of all item variances | Raw data | public double rawMinimumOfItemVariances() | |
| Standardized data | public double standardizedMinimumOfItemVariances() | ||
| Range of all item variances | Raw data | public double rawRangeOfItemVariances() | |
| Standardized data | public double standardizedRangeOfItemVariances() | ||
| Item maxima | Maxima of all items | Raw data | public double[] rawItemMaxima() |
| Standardized data | public double[] standardizedItemMaxima() | ||
| Maximum of an individual item | Raw data | public double rawItemMaximum(int index) | |
| public double rawItemMaximum(String name) | |||
| Standardized data | public double standardizedItemMaximum(int index) | ||
| public double standardizedItemMaximum(String name) | |||
| Mean value of all item maxima | Raw data | public double rawMeanOfItemMaxima() | |
| Standardized data | public double standardizedMeanOfItemMaxima() | ||
| Standard deviation of all item maxima | Raw data | public double rawVarianceOfItemMaxima() | |
| Standardized data | public double standardizedVarianceOfItemMaxima() | ||
| Variance of all item maxima | Raw data | public double rawVarianceOfItemMaxima() | |
| Standardized data | public double standardizedVarianceOfItemMaxima() | ||
| Maximum of all item maxima | Raw data | public double rawMaximumOfItemMaxima() | |
| Standardized data | public double standardizedMaximumOfItemMaxima() | ||
| Minimum of all item maxima | Raw data | public double rawMinimumOfItemMaxima() | |
| Standardized data | public double standardizedMinimumOfItemMaxima() | ||
| Range of all item maxima | Raw data | public double rawRangeOfItemMaxima() | |
| Standardized data | public double standardizedRangeOfItemMaxima() | ||
| Item minima | Minima of all items | Raw data | public double[] rawItemMinima() |
| Standardized data | public double[] standardizedItemMinima() | ||
| Minimum of an individual item | Raw data | public double rawItemMinimum(int index) | |
| public double rawItemMinimum(String name) | |||
| Standardized data | public double standardizedItemMinimum(int index) | ||
| public double standardizedItemMinimum(String name) | |||
| Mean value of all item minima | Raw data | public double rawMeanOfItemMinima() | |
| Standardized data | public double standardizedMeanOfItemMinima() | ||
| Standard deviation of all item minima | Raw data | public double rawVarianceOfItemMinima() | |
| Standardized data | public double standardizedVarianceOfItemMinima() | ||
| Variance of all item minima | Raw data | public double rawVarianceOfItemMinima() | |
| Standardized data | public double standardizedVarianceOfItemMinima() | ||
| Minimum of all item minima | Raw data | public double rawMinimumOfItemMinima() | |
| Standardized data | public double standardizedMinimumOfItemMinima() | ||
| Minimum of all item minima | Raw data | public double rawMinimumOfItemMinima() | |
| Standardized data | public double standardizedMinimumOfItemMinima() | ||
| Range of all item minima | Raw data | public double rawRangeOfItemMinima() | |
| Standardized data | public double standardizedRangeOfItemMinima() | ||
| Item ranges | Ranges of all items | Raw data | public double[] rawItemRanges() |
| Standardized data | public double[] standardizedItemRanges() | ||
| Range of an individual item | Raw data | public double rawItemRange(int index) | |
| public double rawItemRange(String name) | |||
| Standardized data | public double standardizedItemRange(int index) | ||
| public double standardizedItemRange(String name) | |||
| Mean value of all item ranges | Raw data | public double rawMeanOfItemRanges() | |
| Standardized data | public double standardizedMeanOfItemRanges() | ||
| Standard deviation of all item ranges | Raw data | public double rawVarianceOfItemRanges() | |
| Standardized data | public double standardizedVarianceOfItemRanges() | ||
| Variance of all item ranges | Raw data | public double rawVarianceOfItemRanges() | |
| Standardized data | public double standardizedVarianceOfItemRanges() | ||
| Minimum of all item ranges | Raw data | public double rawMinimumOfItemRanges() | |
| Standardized data | public double standardizedMinimumOfItemRanges() | ||
| Minimum of all item ranges | Raw data | public double rawMinimumOfItemRanges() | |
| Standardized data | public double standardizedMinimumOfItemRanges() | ||
| Range of all item ranges | Raw data | public double rawRangeOfItemRanges() | |
| Standardized data | public double standardizedRangeOfItemRanges() | ||
| Item medians | Medians of all items | Raw data | public double[] rawItemMedians() |
| Standardized data | public double[] standardizedItemMedians() | ||
| Median of an individual item | Raw data | public double rawItemMedian(int index) | |
| public double rawItemMedian(String name) | |||
| Standardized data | public double standardizedItemMedian(int index) | ||
| public double standardizedItemMedian(String name) | |||
| Mean value of all item medians | Raw data | public double rawMeanOfItemMedians() | |
| Standardized data | public double standardizedMeanOfItemMedians() | ||
| Standard deviation of all item medians | Raw data | public double rawVarianceOfItemMedians() | |
| Standardized data | public double standardizedVarianceOfItemMedians() | ||
| Variance of all item medians | Raw data | public double rawVarianceOfItemMedians() | |
| Standardized data | public double standardizedVarianceOfItemMedians() | ||
| Minimum of all item medians | Raw data | public double rawMinimumOfItemMedians() | |
| Standardized data | public double standardizedMinimumOfItemMedians() | ||
| Minimum of all item medians | Raw data | public double rawMinimumOfItemMedians() | |
| Standardized data | public double standardizedMinimumOfItemMedians() | ||
| Range of all item medians | Raw data | public double rawRangeOfItemMedians() | |
| Standardized data | public double standardizedRangeOfItemMedians() | ||
| Item totals | Totals of all items | Raw data | public double[] rawItemTotals() |
| Standardized data | public double[] standardizedItemTotals() | ||
| Total of an individual item | Raw data | public double rawItemTotal(int index) | |
| public double rawItemTotal(String name) | |||
| Standardized data | public double standardizedItemTotal(int index) | ||
| public double standardizedItemTotal(String name) | |||
| Mean value of all item totals | Raw data | public double rawMeanOfItemTotals() | |
| Standardized data | public double standardizedMeanOfItemTotals() | ||
| Standard deviation of all item totals | Raw data | public double rawVarianceOfItemTotals() | |
| Standardized data | public double standardizedVarianceOfItemTotals() | ||
| Variance of all item totals | Raw data | public double rawVarianceOfItemTotals() | |
| Standardized data | public double standardizedVarianceOfItemTotals() | ||
| Minimum of all item totals | Raw data | public double rawMinimumOfItemTotals() | |
| Standardized data | public double standardizedMinimumOfItemTotals() | ||
| Minimum of all item totals | Raw data | public double rawMinimumOfItemTotals() | |
| Standardized data | public double standardizedMinimumOfItemTotals() | ||
| Range of all item totals | Raw data | public double rawRangeOfItemTotals() | |
| Standardized data | public double standardizedRangeOfItemTotals() | ||
| Item Moment Skewness | Moment skewness of all items | Raw data | public double[] rawItemMomentSkewnessess() |
| Standardized data | public double[] standardizedItemMomentSkewnessess() | ||
| Moment skewness of an individual item | Raw data | public double rawItemMomentSkewness(int index) | |
| public double rawItemMomentSkewness(String name) | |||
| Standardized data | public double standardizedItemMomentSkewness(int index) | ||
| public double standardizedItemMomentSkewness(String name) | |||
| Item Median Skewness | Median skewness of all items | Raw data | public double[] rawItemMedianSkewnessess() |
| Standardized data | public double[] standardizedItemMedianSkewnessess() | ||
| Median skewness of an individual item | Raw data | public double rawItemMedianSkewness(int index) | |
| public double rawItemMedianSkewness(String name) | |||
| Standardized data | public double standardizedItemMedianSkewness(int index) | ||
| public double standardizedItemMedianSkewness(String name) | |||
| Item Quartile Skewness | Quartile skewness of all items | Raw data | public double[] rawItemQuartileSkewnessess() |
| Standardized data | public double[] standardizedItemQuartileSkewnessess() | ||
| Quartile skewness of an individual item | Raw data | public double rawItemQuartileSkewness(int index) | |
| public double rawItemQuartileSkewness(String name) | |||
| Standardized data | public double standardizedItemQuartileSkewness(int index) | ||
| public double standardizedItemQuartileSkewness(String name) | |||
| Item Excess Kurtosis | Excess kurtoses of all items | Raw data | public double[] rawItemExcesskurtoses() |
| Standardized data | public double[] standardizedItemExcesskurtoses() | ||
| Excess kurtosis of an individual item | Raw data | public double rawItemExcessKurtosis(int index) | |
| public double rawItemExcessKurtosis(String name) | |||
| Standardized data | public double standardizedItemExcessKurtosis(int index) | ||
| public double standardizedItemExcessKurtosis(String name) | |||
| Item Names and Indices | Names of the used items | public String[] itemNames() | |
| Item names as entered | public String[] originalItemNames() | ||
| Deleted item names | public String[] deletedItemNames() | ||
| Index of an item | public int itemIndex(String name) | ||
| Name of an item | public String itemName(int index) | ||
| Number of Items | Number of items used | public int usedNumberOfItems() | |
| Number of items entered | public int originalNumberOfItems() | ||
| Number of items deleted | public int numberOfDeletedItems() | ||
| Person Means | Mean values of all persons | Raw data | public double[] rawPersonMeans() |
| Standardized data | public double[] standardizedPersonMeans() | ||
| Mean of an individual person | Raw data | public double rawPersonMean(int index) | |
| Standardized data | public double standardizedPersonMean(int index) | ||
| Person Standard Deviations | Standard deviations of all persons | Raw data | public double[] rawPersonStandardDeviations() |
| Standardized data | public double[] standardizedPersonStandardDeviations() | ||
| Standard deviation of an individual person | Raw data | public double rawPersonStandardDeviation(int index) | |
| Standardized data | public double standardizedPersonStandardDeviation(int index) | ||
| Person Variances | Variances of all persons | Raw data | public double[] rawPersonVariances() |
| Standardized data | public double[] standardizedPersonVariances() | ||
| Variance of an individual person | Raw data | public double rawPersonVariance(int index) | |
| Standardized data | public double standardizedPersonVariance(int index) | ||
| Person Maxima | Maxima of all persons | Raw data | public double[] rawPersonMaxima() |
| Standardized data | public double[] standardizedPersonMaxima() | ||
| Maximum of an individual person | Raw data | public double rawPersonMaximum(int index) | |
| Standardized data | public double standardizedPersonMaximum(int index) | ||
| Person Minima | Minima of all persons | Raw data | public double[] rawPersonMinima() |
| Standardized data | public double[] standardizedPersonMinima() | ||
| Minimum of an individual person | Raw data | public double rawPersonMinimum(int index) | |
| Standardized data | public double standardizedPersonMinimum(int index) | ||
| Person Ranges | Ranges of all persons | Raw data | public double[] rawPersonRanges() |
| Standardized data | public double[] standardizedPersonRanges() | ||
| Range of an individual person | Raw data | public double rawPersonRange(int index) | |
| Standardized data | public double standardizedPersonRange(int index) | ||
| Person Totals | Totals of all persons | Raw data | public double[] rawPersonTotals() |
| Standardized data | public double[] standardizedPersonTotals() | ||
| Total of an individual person | Raw data | public double rawPersonTotal(int index) | |
| Standardized data | public double standardizedPersonTotal(int index) | ||
| Person Indices | Indices of the used persons | public String[] personIndices() | |
| Deleted person indices | public String[] deletedPersonsIndices() | ||
| Number of Persons | Number of Persons used | public int usedNumberOfPersons() | |
| Number of persons entered | public int originalNumberOfPersons() | ||
| Number of persons deleted | public int numberOfDeletedPersons() | ||
| All responses | Mean | Raw data | public double rawAllResponsesMean() |
| Standardized data | public double standardizedAllResponsesMean() | ||
| Standard Deviation | Raw data | public double rawAllResponsesStandardDeviation() | |
| Standardized data | public double standardizedAllResponsesStandardDeviation() | ||
| Variance | Raw data | public double rawAllResponsesVariance() | |
| Standardized data | public double standardizedAllResponsesVariance() | ||
| Minimum | Raw data | public double rawAllResponsesMinimum() | |
| Standardized data | public double standardizedAllResponsesMinimum() | ||
| Maximum | Raw data | public double rawAllResponsesMaximum() | |
| Standardized data | public double standardizedAllResponsesMaximum() | ||
| Range | Raw data | public double rawAllResponsesRange() | |
| Standardized data | public double standardizedAllResponsesRange() | ||
| Total | Raw data | public double rawAllResponsesTotal() | |
| Standardized data | public double standardizedAllResponsesTotal() | ||
| Responses | Original responses | as entered | public Object originalScores() |
| as row per item | public double[][] originalScoresAsRowPerItem() | ||
| as row per person | public double[][] originalScoresAsRowPerPerson() | ||
| Used responses (Raw data) | as row per item | public double[][] usedScoresAsRowPerItem() | |
| as row per person | public double[][] usedScoresAsRowPerPerson() | ||
| Used responses (Standardized data) | as row per item | public double[][] standardizedScoresAsRowPerItem() | |
| as row per person | public double[][] standardizedScoresAsRowPerPerson() | ||
| Replaced responses | item name and person index of replacements | public String[] indicesOfReplacedScores() | |
| Number of responses | original number | public int originalTotalNumberOfScores() | |
| number used | public int usedTotalNumberOfScores() | ||
| number deleted | public int numberOfDeletedScores() | ||
| number of missing responses replaced | public int numberOfReplacedScores() | ||
| Conversions | Convert to Cronbach | public Cronbach toCronbach() | |
| Convert to PCA | public PCA toPCA() | ||
|
Format A readScoresAsRowPerPersonA Title Number of items Number of persons Row of item names Matrix of scores arranged as rows starting with the person name then scores for that person with separators, e.g. space, comma. details |
Format B readScoresAsRowPerPersonB Title Number of items Number of persons Row of item names Row of person names Matrix of scores arranged as row per person with separators, e.g. space, comma. details |
Format C readScoresAsRowPerPersonC Scores only Matrix of scores arranged as row per person with separators, e.g. space, comma. details |
3 readScoresAsRowPerPersonD Scores only Matrix of single character scores arranged as row per person WITHOUT separators, e.g. 1101011 details |
|
Replaced methods readScoresAsRowPerPerson |
|||
|
|
|
|
|
|
|
|
|
Format A readScoresAsRowPerItemA Title Number of items Number of persons Row of item names Matrix of scores arranged as rows starting with the item name then scores for that item with separators, e.g. space, comma. details |
Format B readScoresAsRowPerItemB Title Number of items Number of persons Row of item names Row of person names Matrix of scores arranged as row per item with separators, e.g. space, comma. details |
Format C readScoresAsRowPerItemC Scores only Matrix of scores arranged as row per item with separators, e.g. space, comma. details |
Format D readScoresAsRowPerItemD Scores only Matrix of single character scores arranged as row per item WITHOUT separators, e.g. 1101011 details |
|
Replaced methods readScoresAsRowPerItem |
|||
|
|
|
|
|
|
|
|
Non-dichotomous data
The method declareDataDichotomous() must have been called if the following replacements are to operate.
See Resetting dichotomous pair representation for changing the default values. |
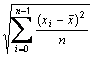
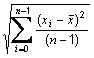
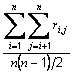
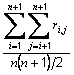
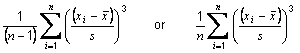
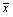 is the sample mean of the item and s is the sample standard deviation of the item.
is the sample mean of the item and s is the sample standard deviation of the item.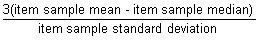
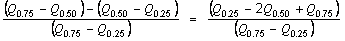
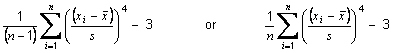 is the sample mean of the item and s is the sample standard deviation opf the item, i.e. returns the kurtosis of the item minus the kurtosis of a Gaussian distribution (3.0).
is the sample mean of the item and s is the sample standard deviation opf the item, i.e. returns the kurtosis of the item minus the kurtosis of a Gaussian distribution (3.0).