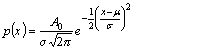This application analyses a set of examination marks, provided by the user, and examines the fit of the marks to a Gaussian (normal) distribution function, p(x):
The marks may be supplied as a text file with either a single column or a single row of marks.
The application performs the following:
Calculation of the mean, standard deviation, skewness and kurtosis.
Offers the option of scaling the marks. The following scaling options are available:
No scaling.
Multiplicative scaling factor.
Additive scaling factor.
Scaling to a new mean and/or standard deviation.
Fits the marks to a Gaussian distribution using a Gaussian probability plot.
Converts the data to a histogram.
Fits the histogram bin centres and frequencies to a Gaussian distribution using non-linear regression.
Displays graphs of the plotted fits.
Reports parameters indicating the goodness, or otherwise, of the fits.
Reports the values of μ, σ and Ao and their estimated errors.
INSTALLING AND RUNNING THE APPLICATION GaussianFit
The Java Development Kit Platform listed on this library's main page must be installed on your computer or network [jdk1.8.0. on 2 February 2015].
This application creates instances of, and calls methods from, the ProbabilityPlot and the Regression classes facilitating the fitting of the marks to a Gaussian distribution. These classes are part of the Michael Thomas Flanagan Library. The Michael Thomas Flanagan Library file, flanagan.jar, must be downloaded and installed in the appropriate directory. See Michael Thomas Flanagan Library Main Page for flanagan.jar download and instal instructions.
Download the source file GaussianFit.java into an appropriate folder.
Compile GaussianFit, e.g on PC with a Microsoft Windows XP Operating System:
Open up the Command Prompt Window
Change to the directory in which you have stored GaussianFit.java, e.g. type cd c:\Marks where Marks is the name of that folder on the C drive.
Compile, i.e. type javac GaussianFit.java followed by a return
PREPARING THE DATA FILE
Prepare the input data file. The data file may be stored in any directory. It is not necessary to store it in the same directory as PCA_Analysis but such storage may be convenient.
The data file must be a text file of the one of the two following formats:
A one line title.
A list of the examination marks with each mark on a separate line.
Each mark may be represented by an integer or floating point number.
A missing mark must be indicated by an alphabetic character or word, e.g. ABS.
Example of such a data file: GaussDataOne.txt
A one line title.
A list of the examination marks as a single line of integer or floating point numbers.
The individual marks must be separated by a space or spaces, a comma, a semicolon, a colon or a tab.
A missing mark must be indicated by an alphabetic character or word, e.g. ABS.
Example of such a data file: GaussDataTwo.txt
The FitToGaussian program will recognize which format has been chosen.
RUNNING GaussianFit
Run GaussianFit, e.g on PC with a Microsoft Operating System:
Open up the Command Prompt Window
Change to the directory in which you have stored GaussianFit.java, e.g. type cd c:\Marks where Marks is the name of that folder on the C drive.
Run, i.e. type java GaussianFit followed by a return
A series of information or dialogue boxes will then appear sequentially. All you need to do is respond`to each box in turn. Pressing the ‘enter’ key will close the box selecting the default option, i.e. the button with the bold outline or the value or text in the text box.
Box one: Information box
The first box is an information message identifying the Program that you have initiated. Click on the OK button when you have read the message.
Box two: Selection of the input data file
This file slection window allows you to select the data file you wish to analyse.
This window opens displaying the contents of the current directory, i.e. the directory in which you have stored GaussianFit.java, but you can use this window to browse any directory on your computer if you have not stored your data files in the current directory.
Box three: Remove negative values and values above 100
This dialogue box only appears if the entered marks data contains negative values and/or values above 100. If this is the case you are offered the two options:
Leave the entered data as entered.
Replace all negative values by zero and replace all values greater than 100 by the value 100.
Box four: Scale the data
This dialogue box displays the mean and standard deviation of the entered data and offers the option of scaling the data. If you choose not to scale the data go to Box eleven.
Box five: Scaling options
This dialogue box only appears if you have chosen to scale the marks. It offers the following scaling options.
Multiply each mark by a scaling factor
Add or subtract a scaling factor to or from each mark
Scale the data to a new mean and/or a new standard deviation
Box six: Multiplicative scaling options
This dialogue box only appears if you have chosen to use a simple multiplicative scaling factor. It requests that you enter the value of the scaling factor.
Box seven: Additive or subtractive scaling options
This dialogue box only appears if you have chosen to use a simple additive or subtractive scaling factor. It requests that you enter the value of the scaling factor. enter a positivee value for addition and a negative value for subtraction.
Box eight: Scale to a new mean
This dialogue box only appears if you have chosen to scale to a new mean and/or standard deviation. It requests that you enter the value of the new mean.
Box nine: Scale to a new standard deviation
This dialogue box only appears if you have chosen to scale to a new mean and/or standard deviation. It requests that you enter the value of the new standard deviation.
Box ten: Remove negative values and values above 100
This dialogue box only appears if your rescaling has created negative values and/or values greater than 100. If this is the case you are offered the two options:
Leave the scaled data as it is.
Replace all negative values by zero and replace all values greater than 100 by the value 100.
Boxes eleven: ProbabilityPlot display and histogram request Gaussian Probability Plot
A graph of the Gausssian probability plot, i.e. the best fit of the ordered data values versus the Gaussian order statistic medians, is displayed. Histogram request
The data are arranged in the form of an histogram to facilitate a non-linear regression. This box displays the histogram marks bin width used and requests you to enter the value of the bin width that you would prefer. The entered value overrides the displayed value.
Boxes twelve: Non-linear regression plot display and output file request Gaussian Non-linear Regression Plot
A plot of the marks histogram and the best fit to this histogram using non-linear regression and a Gausssian probability function is displayed. Output file request
This dialogue box offers the options, for the output file listing details of the analyses, of:
A text file (.txt)
An Excel readable file (.xls)
The output file contains the following analysis
Title
Name of input file if data read from a text file
Time and date of program execution
Mean, standard deviation, moment skewness, median skewness, quartile skewness and excess kurtosis of the marks
Gaussian Probabilty Plot Analysis
The program calculates the best fit Gaussian probability plot by varying the values of the Gaussian μ and σ.
Best estimates of the Gaussian μ and σ and their estimated errors.
Linear correlation coefficient of the ordered data values and the Gaussian order statistic medians for the best fit values of μ and σ
Values of the gradient and intercept of the ordered data values plotted against the Gaussian order statistic medians for the best fit values of μ and σ
Estimates of the errors of the above gradient and intercept
Values of the ordered data values and of the Gaussian order statistic medians for the best fit values of μ and σ
Non-linear Regression Analysis
The program collects the data into a series of histogram bins and uses these to calculate the best fit to the Gaussian probability function using a Nelder and Mead simplex non-linear regression.
Best estimates of the Gaussian μ, σ and Ao and their estimated errors
Linear correlation coefficient of the experimental data and calculated data for the best fit values of μ, σ and Ao.
Coefficient of determination.
Coefficient of determination F-ratio.
Histogram bin width.
Values of the experimental binned data frequencies and of the calculated values for the best fit values of μ, σ and Ao.
A list of the entered marks and, if scaling has occurred, a list of the scaled marks.
Box thirteen: Output file name
This input box requests that you enter the name of the output file. The default name is the name of the input file with Analysis added as a suffix, e.g. an input file named GaussDataOne.txt gives a default name for the output file as GaussDataOneAnalysis.txt.
Box fourteen: Closure request
This dialogue box gives you the option of terminating the program and closing the two graph windows now or later.
If you choose to leave the Plots displayed (clicking on NO) you need to end the program later by clicking on the close icon (white cross on red background in the top right hand corner) on the plot, or if using a Microsoft operating system, typing Control C in the command prompt window.
Clicking on the NO button ends the program and closes the graph windows.
The output files are created in the directory in which you compiled GaussianFit unless you included an alternative path in a supplied output file name.
EXAMPLE PROGRAMS
Example Program Data Files GaussDataOne.txt is an input file in which the marks are listed as each mark on a new line.
GaussDataTwo.txt is an input file in which the marks are listed as a single line separated by spaces.
Example Program Output Files No rescaling and .txt option
The output file, produced on running the GaussFit application with the above input data, GaussDataOne.txt, and choosing:
With rescaling and .xls option
The output file, produced on running the GaussFit application with the above input data, GaussDataTwo.txt, and choosing:
Rescaling of the data to a new mean and new standard deviation
Rounding scaled values avove 100 to 100
Excel readable file (.xls) as the output file type
See also ProbabilityPlot class, a class underpinning this application, for a more detailed description of methods called by this application.
Non-linear Regression
Nelder, J.A. and Mead, R. (1965) Computer Journal, 7, 308-313.
See also Regression class, a class underpinning this application, for a more detailed description of methods called by this application.
Statistics
See also Stat class, a class underpinning this application, for a more detailed description of methods called by this application and for definitions of the statistics used in this application.
PERMISSION TO USE
Permission to use, copy and modify this software and its documentation for NON-COMMERCIAL purposes is granted, without fee, provided that an acknowledgement to the author, Dr Michael Thomas Flanagan at www.ee.ucl.ac.uk/~mflanaga, appears in all copies and associated documentation or publications.
Public listing of the source codes on the internet is not permitted.
Redistribution of the source codes or of the flanagan.jar file is not permitted.
Redistribution in binary form of all or parts of these classes is not permitted.
Dr Michael Thomas Flanagan makes no representations about the suitability or fitness of the software for any or for a particular purpose. Dr Michael Thomas Flanagan shall not be liable for any damages suffered as a result of using, modifying or distributing this software or its derivatives.